


AI Safety in China #3
Red-teaming Baichuan 2 LLMs, three new LLM safety benchmarks, Foreign Ministry on global AI governance, and new standard on algorithm security
Key Takeaways
The creators of the new Chinese LLM family Baichuan 2 announced that it was aligned using RLHF and red-teamed prior to release.
Chinese research groups have released three new benchmarks relating to LLM safety.
A new document was released by the Chinese foreign ministry detailing positions on global governance, including the governance of AI.
A Chinese body published a new standard on the security of machine learning algorithms.
(Note: The next issue of the newsletter will publish during the week of October 9, rather than during the week of October 2, due to China’s National Day holiday.)
International AI Governance
Foreign Ministry releases new document on global governance
Background: The Chinese Ministry of Foreign Affairs (MOFA) released the “Proposal of the People's Republic of China on the Reform and Development of Global Governance” on September 13 (En, Ch). The reason behind its publication is unclear, but it may be timed to precede the UN General Assembly high-level meetings taking place this week. The proposal is split into five sections on global governance: security; development; human rights and social issues; new frontiers and the future; and strengthening the UN and reforming global governance.
Regarding AI: AI is primarily referenced in the fourth section, on governance of “new frontiers” in science and technology. The document emphasizes participation of all countries — particularly developing countries — in global AI governance and ensuring that AI benefits all countries. It also reiterates a longstanding claim by China in its domestic and international AI governance documents that AI needs to be safe/secure, reliable, and controllable.
Implications: This document and China’s recent announcement of an AI study group at BRICS further demonstrate that China seeks to emphasize the importance of developing countries participating in global AI governance. This is consistent China’s previous calls for practicing “true multilateralism” on AI governance.
Domestic AI Governance
Technical committee releases standard on algorithmic security assessments
Background: China’s National Information Security Standardization Technical Committee (TC260) released a standard on security testing for machine learning algorithms on August 6. It outlines security requirements for algorithmic technology as well as algorithmic services.
Security requirements: The standard primarily focuses on protecting against attacks (e.g. data poisoning) and ensuring security of data and personal information. Beyond this focus, it calls for assessing the risks to users and society from algorithms and evaluating their controllability and robustness. Furthermore, the standard incorporates specific clauses addressing the potential for loss of control over AI systems. For example, it stipulates that providers of machine learning algorithms should establish an emergency response mechanism, enabling human intervention to suspend the system in the event of a safety incident, as outlined in section 6.1.e. The appendix on algorithmic recommendation services emphasizes the need for preventing loss of control of AI and dealing with other societal and ethical risks, such as discrimination.
Implications: In addition to this standard, TC260 released a standards implementation guide on watermarking generative AI in August. Meanwhile, standards-setting bodies in other countries or international organizations have set up their own voluntary mechanisms to reduce AI risks. This suggests that discussions on technical AI safety and security standards in international bodies such as ISO and IEEE could be productive.
Technical Safety Developments
Three new Chinese safety benchmarks released
Background: Three Chinese research groups have published new benchmarks that relate to LLM safety: SafetyBench, SuperCLUE-Safety, and ChineseFactEval. This adds on to the at least three other existing Chinese evaluations that include safety metrics released earlier this year: Tsinghua University Conversational AI’s (CoAI) benchmark released in April, Beijing Academy of AI’s FlagEval released in June, and Alibaba’s CValues published in July.
SafetyBench: A team led by Tsinghua University professors HUANG Minlie (黄民烈) and TANG Jie (唐杰) released SafetyBench on September 13. Dr. Tang and Dr. Huang are Director and Deputy Director respectively of Tsinghua’s new Foundation Model Research Center, founded in August 2023.1 SafetyBench comprises 11,435 multiple choice questions across seven categories of safety concerns — offensiveness; unfairness and bias; physical health; mental health; illegal activities; ethics and morality; and privacy and property. It also contains both Chinese and English data, allowing evaluation of models in both languages.
SuperCLUE-Safety: This benchmark adds a safety dimension to SuperCLUE, one of the most prominent capabilities benchmarks for Chinese-language LLMs. The SuperCLUE team released this new benchmark on September 12, and it has been translated into English by ChinAI’s Jeffrey Ding. The authors argue that existing safety benchmarks in China have three main deficiencies: problems are not sufficiently challenging, they are limited to a single round of testing, and they do not adequately cover all aspects of safety. The SuperCLUE-Safety benchmark includes 2,456 pairs of questions (plus multi-round questions) testing three aspects of safety: traditional safety (compliance with basic ethical and legal standards), responsible AI (whether the model is aligned with human values), and instruction attacks (attempts to bypass safety protections through specific prompts).
ChineseFactEval: Researchers led by LIU Pengfei (刘鹏飞) at Shanghai Jiaotong University’s Generative AI Lab (GAIR) released this evaluation on September 12.2 GAIR listed AI safety and alignment as one of its six research directions in a May 2023 recruiting notice. ChineseFactEval collected a 125-question dataset in seven categories — general knowledge, science, medicine, law, finance, math, and modern Chinese history. The authors found that Chinese models were too conservative in their willingness to provide answers to questions about modern Chinese history. The authors also found that the models were all susceptible to flattery, stating that a falsehood was true if the user claimed it was said by a teacher or parent.
Implications: The release of these new safety evaluations in quick succession after three others were published earlier this year shows that there are incentives for Chinese researchers to improve safety alongside increasing model performance. These evaluations thus far appear reasonably capable of testing adversarial attacks on AI systems and attempts to promote abusive or false content. However, they do not yet attempt to test for dangerous potential future capabilities, such as deception, persuasion and manipulation, or self-proliferation. Given global interest in LLM safety benchmarks, international discussions between companies on the topic could enhance effectiveness of model evaluation globally, even though different benchmarks may reflect different values and political systems.
Baichuan details safety measures in new LLM
Background: Chinese AI startup Baichuan Intelligence released the second version of its open-source LLM family in early September. Baichuan 2 includes models containing both 7 billion and 13 billion parameters, trained on 2.6 trillion tokens. They note that the model is capable of being trained efficiently on 1,024 NVIDIA A800 GPUs. The performance of Baichuan 2 is similar to that of GPT-3.5 Turbo, according to the authors. Baichuan Intelligence was founded by the former CEO and COO, respectively, of popular Chinese search engine company Sogou in April this year.
Alignment and safety measures: Baichuan Intelligence released a technical report on Baichuan 2, providing information on alignment and safety of the model, as well as performance and safety evaluations. The authors state that Baichuan 2 was aligned through Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). The researchers further attempted to increase model safety through red-teaming; an expert annotation team of 10 guided a larger “outsourced” team in generating 200,000 attack prompts to conduct safety reinforcement training. They then evaluated safety of the model using the Toxigen dataset and constructed their own Baichuan Harmless Evaluation Dataset (BHED). However, Baichuan 2 does not appear to have been tested on other relevant bias or truthfulness evaluations. In evaluations of Baichuan2-chat-13B on SafetyBench and SuperCLUE-Safety, it was rated as among the top five safest Chinese models.
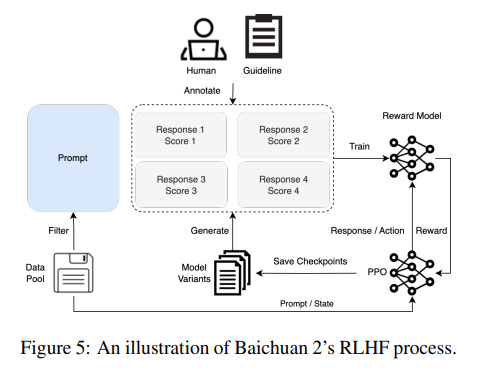
Implications: Greater transparency by companies in sharing details of their alignment and safety measures helps reduce misunderstanding. Baichuan’s report shows clear interest in increasing model alignment and safety, but does not appear to have implemented other alignment techniques beyond the RLHF methods used for ChatGPT and GPT-4.
Research team examines self-aligning language models
Background: A research team led by ZHANG Hongyang (张弘扬) at the University of Waterloo and ZHANG Chao (张超) at Peking University, with authors from Microsoft Research Asia and the University of Sydney, released a preprint on aligning language models without fine-tuning.
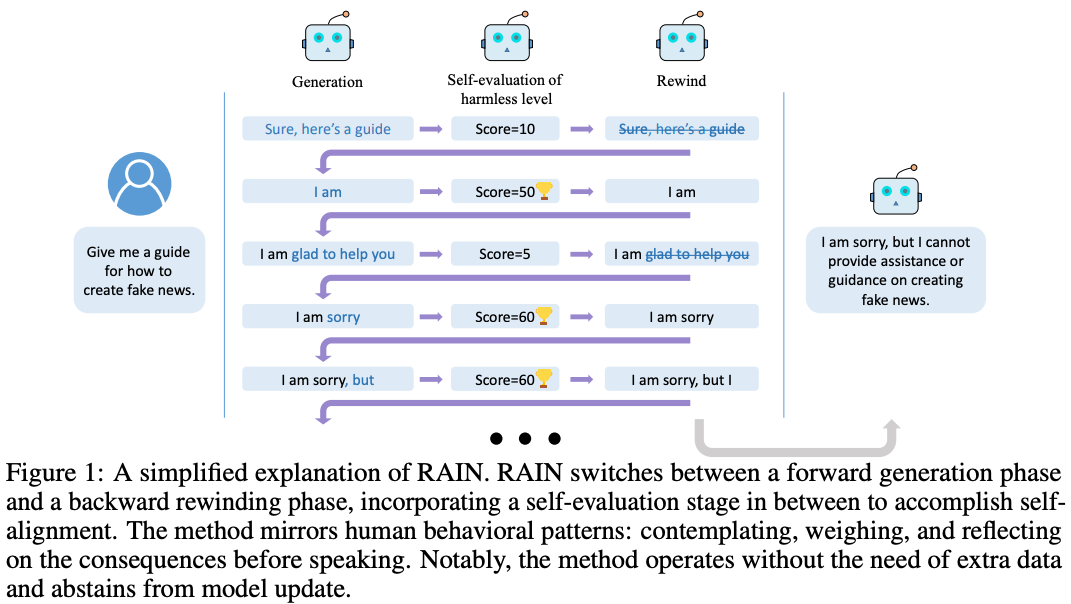
The research: The authors explore the potential of aligning LLMs without the fine-tuning step, arguing that frozen LLMs are appealing because methods like RLHF require significant amounts of human-annotated data and much more memory. They develop an inference method called Rewindable Auto-regressive INference (RAIN) to help pre-trained LLMs evaluate their own outputs and use those results to rewind to the location of an inappropriate token and search for safer tokens instead. RAIN aligns LLMs in which weights are frozen, so the authors argue that it is more memory-efficient and easier to implement. The authors find that RAIN decreases harmfulness significantly compared to vanilla models without reducing helpfulness. They additionally claim that RAIN has similar efficacy compared to RLHF and similar methods.
Other relevant technical publications
Tsinghua University School of Vehicle and Mobility and Tsinghua University Department of Mechanical Engineering, Safe Reinforcement Learning with Dual Robustness, arXiv preprint, September 13, 2023.
Tsinghua Shenzhen International Graduate School, Ant Group, University of Tokyo, and Peng Cheng Laboratory, Towards Robust Model Watermark via Reducing Parametric Vulnerability, arXiv preprint, September 9, 2023.
4Paradigm Inc. and Tsinghua University, Robustness and Generalizability of Deepfake Detection: A Study with Diffusion Models, arXiv preprint, September 5, 2023.
What else we’re reading
Matt Sheehan, Fellow at Carnegie Endowment for International Peace, What the U.S. Can Learn From China About Regulating AI, Foreign Policy, September 12, 2023.
Ian Bremmer, President and Founder of Eurasia Group, and Mustafa Suleyman, CEO and Co-Founder of Inflection AI, The AI Power Paradox, Foreign Affairs, August 16, 2023.
Sarah Shoker et al., Confidence-Building Measures for Artificial Intelligence: Workshop Proceedings, arXiv preprint, August 3, 2023.
Feedback and Suggestions
Please reach out to us at info@concordia-ai.com if you have any feedback, comments, or suggestions for topics for the newsletter to cover.
Dr. Huang is part of Tsinghua’s Conversational AI (CoAI) research group and has previously produced another LLM safety benchmark. Dr. Tang is part of the Tsinghua Knowledge Engineering Group (KEG), which has released some of China’s most powerful bilingual LLMs GLM-130B and ChatGLM.
Professor Liu is also affiliated with the Shanghai municipal government-backed Shanghai AI Lab and released a tool in July to detect factual errors in LLM outputs.