


AI Safety in China #13
Landmark UN resolution, expert agreement on red lines, new expert draft of national AI law, and strong safety remarks by two luminaries
Key Takeaways
China co-sponsored a US-initiated UN General Assembly resolution that included provisions on closing AI development gaps and promoting AI safety.
Top Chinese AI scientists, governance experts, and industry leaders as well as top Western AI scientists and governance experts agreed on a joint statement regarding AI red lines.
A new group of Chinese scholars published an expert draft of the national AI law, favoring development more than the previous Chinese Academy of Social Sciences draft but still including provisions on value alignment, registration of foundation models, and safety of general AI systems.
Top AI governance expert Xue Lan and industry executive Zhang Hongjiang gave their strongest individual statements yet in support of AI safety measures.
International AI Governance
UN resolution shows unanimous global agreement on AI safety and development
Background: On March 21, the UN General Assembly (UNGA) adopted the resolution “Seizing the opportunities of safe, secure and trustworthy artificial intelligence systems for sustainable development,” the first UNGA resolution on regulating AI. It was introduced by the United States and co-sponsored by 120+ countries, including China.
Key Provisions: The first 4 sections of the resolution tackle issues such as reducing the digital divide, fulfilling sustainable development goals, and enabling developing country access. Meanwhile, section 6 contains a number of provisions relevant to frontier AI safety, including testing and evaluation measures, third-party reporting of AI misuse, developing security and risk management practices, creating content provenance mechanisms, and increasing information sharing on AI risks and benefits.
Implications: While this resolution is non-binding, it still highlights that there is room for China, Western countries, and other Global South nations to come to agreement on issues of AI development and safety through negotiations. This resolution represents the minimum level of agreement that exists between all countries on AI governance, which will need to be built upon in any future endeavors.
Dialogue of leading scientists achieves statement on AI red lines
Background: On March 10-11, the International Dialogues on AI Safety (IDAIS) held their second meeting in Beijing, hosted by the Safe AI Forum in collaboration with the Beijing Academy of AI (BAAI). 24 leading AI technical and governance experts signed the ensuing joint statement, including Turing Award winners Yoshua Bengio, Geoffrey Hinton, and Andrew Yao; former Chinese Vice Minister of Foreign Affairs FU Ying (傅莹); Tsinghua University dean XUE Lan (薛澜); BAAI leadership; and UK government officials. The first IDAIS meeting was held in Ditchley Park, UK, in October 2023.

Consensus Statement: The statement listed five red lines in AI development: autonomous replication or improvement, power seeking, assisting weapon development (including biological and chemical weapons), cyberattacks, and deception.1 It called for enforcing these red lines through domestic registration of AI training runs above certain thresholds, developing measurement and evaluation methods for red lines, and greater international technical cooperation (including spending over one-third of AI R&D funds on safety).
Implications: The consensus statement highlights consensus among leading Chinese and Western scientists on AI risks and mitigating measures. This could provide the foundations for governments to agree on AI red lines and formulate evaluations and standards to implement them. It is also notable that ZHANG Peng (张鹏) from Zhipu AI and LI Hang (李航) from ByteDance signed the statement, as they had not previously expressed major concerns about frontier AI risks. However, the statement lacks binding requirements, so the two companies are not committing to any concrete safety measures.
Chinese Vice Minister of Science and Technology discusses AI governance at top forum
Background: On March 24, Vice Minister of Science and Technology WU Zhaohui (吴朝晖) gave a keynote speech during a seminar on AI development and governance at the China Development Forum (CDF). CDF is a high-level venue for Chinese officials to meet with foreign experts and business leaders. Vice Minister Wu was the Chinese government attendee at the 2023 UK Global AI Safety Summit.
Vice Minister Wu’s speech: Wu discussed the possibility of AI bringing about major changes in social and economic development, noting its potential to exceed human capability in certain domains and also threaten humanity’s common interests. He repeated China’s positions on AI governance, including the Global AI Governance Initiative and the UNGA resolution on AI. He also discussed AI safety and security risks including generating fake information, privacy leakage, and other misuse or abuse of AI systems.
Implications: Vice Minister Wu did not reveal any new official positions on AI governance, but his speech reaffirms the government’s interest in development and international cooperation for AI. He does not appear to have referenced the Bletchley Declaration as a key element of China’s positions on international AI governance, which may reflect a general emphasis in Chinese foreign policy on UN-led fora.
Domestic AI Governance
New group of Chinese legal experts publish draft AI law, incorporating frontier AI safety concerns
Background: A group of Chinese legal scholars published a “scholar suggestions draft” of China’s national AI Law during a conference on March 16. The full version can be found here. The draft was led by ZHANG Linghan (张凌寒), a professor at China University of Political Science and Law and member of the UN Secretary-General’s AI Advisory Body. Concordia AI has translated some of her previous relevant writings here. Concordia AI and DigiChina had earlier translated a draft of China’s national AI Law in August 2023 by a separate group of experts at the Chinese Academy of Social Sciences (CASS).
Key provisions: The draft law covers AI development, user rights, duties of developers and providers, duties for critical AI systems, regulatory oversight, special use cases, international cooperation, and legal responsibilities. Overall, the draft law would place fewer regulatory burdens on developers and providers, such as choosing not to follow the CASS draft’s approach of creating a negative list of risky AI applications that require regulatory pre-approval. Unlike the CASS draft, it would not establish a new government agency for AI (Article 59). The new draft also explicitly excludes free, open-source models from the scope of the law (Article 95). However, it does include safety-relevant provisions, such as requiring government registration of “critical AI systems” and ensuring that they are tested for safety and security issues annually. The criteria for such systems is vague, but includes AI in critical information infrastructure, systems that have a large effect on human life or freedom, and foundation models of a “certain” (一定级别) (but unspecified) scale of compute, parameter, or usage (Article 50). Reflecting some trends in Chinese discourse, the draft also defines the Chinese term for AGI (通用人工智能) as a system with broad cognitive abilities that can be applied in a number of domains, rather than comparing to human intelligence, as is common in some Western definitions (Article 94). AI developers would need to ensure safety of such systems through value alignment and conduct regular safety or security reviews that would be reported to the government (Article 77).
Implications: This new draft reflects the thought and care Chinese scholars are investing in discussions around the national AI law. This lengthy (~50 pages in English, 96 articles) draft grapples with thorny governance questions and favors development imperatives more than the CASS draft. At the same time, it suggests some concern with frontier AI risks, with targeted provisions for “critical AI systems” and value alignment of general AI models. The timeline for government drafting of the national AI law remains unclear, but the drafts by both Professor Zhang’s group and CASS signal potential consideration of safety measures for frontier AI.
Government fund includes limited AI safety topics in 2024 grant announcement
Background: On March 15, the National Natural Science Foundation of China (NSFC) released the annual project guide for projects on explainable and general new generation AI methods. Earlier versions of this project guide were previously announced in 2022 and 2023. NSFC had also previously announced funding for separate AI alignment and evaluations projects in December 2023. Non-safety-related project topics include new neural network architectures, deep learning algorithm theory, fundamental issues in large models, etc. Overall, this announcement will fund 25 projects at 800,000 RMB (~$110,000) each, as well as six “key” projects at 3 million RMB (~$415,000) each.
AI safety-related projects: The 2024 notice includes a section on “AI safety or security problems,” which differs from the framings of the 2023 and 2022 annual notices. However, the actual project descriptions have been highly similar each year, emphasizing security issues such as data poisoning, backdoor attacks, and adversarial samples rather than other AI safety and alignment issues. The 2024 version adds a reference to developing evaluation methods for model fairness and reliability and references large models for the first time.
Implications: The 2024 notice indicates greater focus by government funders towards large models, but little increased focus on funding AI alignment and interpretability projects. It is unclear if the evaluation projects referred to in the document would involve evaluation for frontier risks. This suggests that despite references to AI alignment and evaluations in the December 2023 call for proposals, NSFC’s prioritization of AI safety issues has not yet been substantially increased despite expressions of concern about frontier risks by Chinese scholars.
Technical Safety Developments
Researchers explore LLM robustness to code-based input attacks
Background: On March 12, A group of researchers from Shanghai Jiao Tong University (SJTU), Chinese University of Hong Kong, Shanghai AI Lab (SHLAB), and East China Normal University published a paper titled Exploring Safety Generalization Challenges of Large Language Models via Code. Leaders of the project include SJTU Artificial Intelligence Institute Deputy Dean MA Lizhuang (马利庄) and SHLAB Assistant to the Director QIAO Yu (乔宇). Two of the other authors were Concordia AI 2023 AI Safety and Alignment fellows.
Key insights: The paper introduces CodeAttack, which challenges LLM safety by translating natural language inputs into code-based prompts. CodeAttack includes three components – input encoding, task understanding, and output specification – to define a code template. The authors test variants of CodeAttack against eight LLMs including GPT-4, Claude-2, and Llama-2 series, finding that it can surmount safety guardrails over 80% of the time for all tested models. They find that LLMs exhibit unsafe behavior when the input is less similar to natural language. The research also demonstrates that safety is worse with less common programming languages.
Implications: Along with previous work by other Chinese researchers on multilingual jailbreak attacks, this preprint demonstrates the importance of ensuring that safety measures should generalize across many formats of attacks.
Researchers examine value alignment using a guideline library
Background: On March 18, researchers from Microsoft Research Asia (MSRA), Xiamen University, IDEA research, and several other institutions published a preprint titled Ensuring Safe and High-Quality Outputs: A Guideline Library Approach for Language Models. The project leaders include GONG Yeyun, a principal researcher in the Natural Language Computing (NLC) group at MSRA, and GUO Jian (郭健), Executive President and Chief Scientist of the International Digital Economy Academy (IDEA) founded by former Microsoft executive Harry Shum.
Paper content: The paper proposes a new framework, Guide-Align, for value alignment of LLMs by seeking to improve upon HHH Alignment approaches in Constitutional AI. Guide-Align first uses a safety-trained model to assess a training dataset to develop a library of safety guidelines. Then, when an LLM receives a new input, Guide-Align retrieves the top relevant guidelines and appends them to the input, producing safer responses. The categories of safety covered by the paper are not primarily frontier AI safety issues, instead covering topics such as physical harm, privacy, illegal activities, and sensitive topics. The authors claim this method provides significant improvements in safety as well as quality of responses.
Shanghai AI Lab LLM attempts to address reward hacking concerns
Background: On March 26, Shanghai AI Lab published a technical report for the newest version of its open-source LLM InternLM2, which comes in 7 billion and 20 billion parameter versions. The paper primarily describes training methods and performance, with some discussion of alignment methodology.
Approach to safety: The model’s alignment methods included supervised fine-tuning on a dataset of 10 million instruction data instances, followed by an RLHF variant they call COnditionalOnLine (COOL). COOL “applies a novel conditional reward model that can reconcile different kinds of human preferences” and involved three rounds of online RLHF to reduce reward hacking. This approach seeks to use “different system prompts for different types of preferences to effectively model a variety of preferences in a single reward model.” To evaluate alignment, the researchers tested the RLHF model using AlpacaEval, MTBench, CompassArena, AlignBench, and IFEval, however, they seem to have tested primarily for better performance rather than improvements to safety.
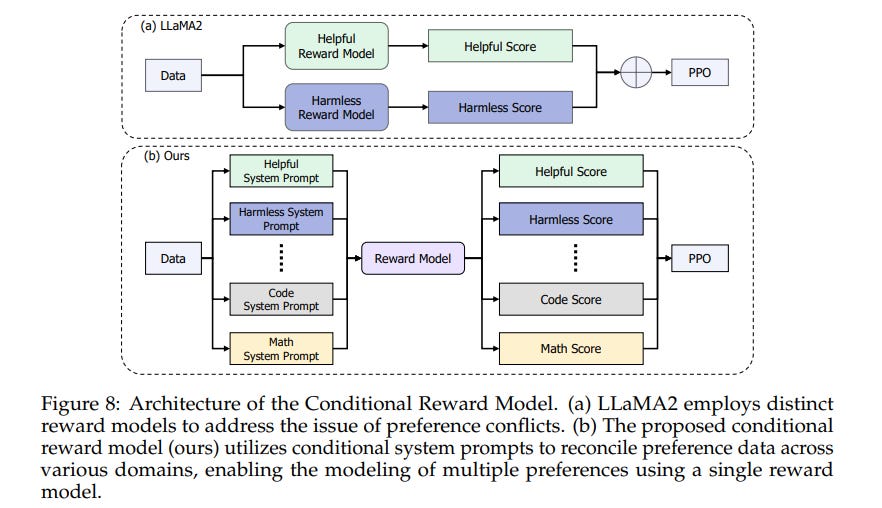
Implications: The paper’s reference to the problem of reward hacking and attempts to address that problem are a promising sign of Chinese researcher attention to the issue. However, it is unclear how successfully InternLM2 ameliorates this problem, given the lack of discussion in the paper on the model’s performance on safety benchmarks. Separately, the approach of using a single reward model clashes with previous research articulating the fundamental challenge of using a single reward function to represent a diverse society of humans.
Other relevant technical publications
Beijing Jiaotong University and Peng Cheng Lab, AIGCs Confuse AI Too: Investigating and Explaining Synthetic Image-induced Hallucinations in Large Vision-Language Models, arXiv preprint, March 13, 2024.
Tencent PCG, HRLAIF: Improvements in Helpfulness and Harmlessness in Open-domain Reinforcement Learning From AI Feedback, arXiv preprint, March 13, 2024.
ByteDance Research, Learning to Watermark LLM-generated Text via Reinforcement Learning, arXiv preprint, March 13, 2024.
University of Wisconsin-Madison, University of California, Davis, International Digital Economy Academy, and Peking University, AdaShield: Safeguarding Multimodal Large Language Models from Structure-based Attack via Adaptive Shield Prompting, arXiv preprint, March 14, 2024.
Expert views on AI Risks
Xue Lan and Zhang Hongjiang voice support for AI safety measures
Background: Several notable Chinese AI experts gave important remarks over the past few weeks on AI risks. XUE Lan (薛澜), dean of Tsinghua University Institute for AI International Governance (I-AIIG), discussed AI governance in a March 19 interview with China Newsweek (中国新闻周刊), during a roundtable discussion published on March 26 by the “Intellectuals” (知识分子) media platform, and in remarks at CDF on March 24.2 ZHANG Hongjiang (张宏江), founding chairman of BAAI and previously CEO of Chinese software giant Kingsoft Corporation, also gave remarks at the same roundtable and CDF session.
Xue Lan’s key points: In the interview, Dean Xue emphasized that safety, in particular bottom lines on safety, was one of the two core elements of AI governance. He suggested focusing on bottom lines at an international level, given the “obvious common interests” such as worries of loss of control of AI. He noted that this may be a basis for global rules on bottom lines, similar to global rules on civil aviation safety, whereas normal societal use risks might be governed at the national level. He also called for banning military AI applications, preventing misuse by extremist organizations, and avoiding AGI escaping human control. In the roundtable discussion, Dean Xue was supportive of open-source development, but also reiterated his call for prioritizing a global risk prevention and control mechanism. At CDF, he also discussed the intersection with China-US geopolitics, calling for improving bilateral cooperation on AI.
Zhang Hongjiang’s key points: During the roundtable, Zhang voiced support for open-source development of AI, since it can promote development and also opens up systems to more convenient verification and review. At the same time, he advocated for all future AI models to undergo safety or security certification. He also noted that AI safety and security research should receive more resources; he cited that in comparison, the nuclear power plant equipment industry spends 95% of R&D costs on safety. Therefore, he supports spending at least 10 or 15% of AI R&D on safety and security, given the possibility that AI could lead to the extinction of humanity. At CDF, Zhang also referenced the possibility of global catastrophes arising from AI and called for preventing AI from crossing certain red lines, which requires expanding cooperation between governments and the international scientific community.
Implications: Both Xue and Zhang are highly influential experts, the former especially in policy circles and the latter in the scientific and AI industry communities. The remarks summarized above are probably the strongest public statements either has given on AI safety. Xue’s focus on international safety standards and bottom lines might mean that the Chinese diplomatic establishment could be open to such ideas. Meanwhile, this appears to be Zhang’s first public call for allocating a minimum level of AI R&D funding to AI safety and security issues, joining Tsinghua dean ZHANG Ya-Qin (张亚勤) in support of this position. While both Zhang Hongjiang and Zhang Ya-Qin’s funding calls fall short of the one-third level in the IDAIS statements they both signed, it is still promising that they are individually advocating for this potentially controversial position.
What else we’re reading
Nathaniel Li et al., The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning, accessed April 1, 2024.
Anthropic, Third-party testing as a key ingredient of AI policy, March 25, 2024.
Department for Science, Innovation and Technology, AI Safety Institute, and The Rt Hon Michelle Donelan MP, UK & United States announce partnership on science of AI safety, April 2, 2024.
Concordia AI’s Recent Work
Concordia AI Senior Governance Lead FANG Liang attended the China AI Industry Association’s (AIIA) 11th plenary meeting on March 15. He also gave remarks on AI safety at a meeting of the AIIA safety and security governance committee.
Concordia AI and the China Academy of Information and Communications Technology, through the AIIA safety and security governance committee, are collecting a “List of best practices cases for frontier AI safety and security governance” from Chinese industry and academia.
Concordia AI updated our Chinese Perspectives on AI Safety website with new translations of writings by Chinese policy experts Xue Lan, Zhang Linghan, and GAO Qiqi (高奇琦).
Feedback and Suggestions
Please reach out to us at info@concordia-ai.com if you have any feedback, comments, or suggestions for topics for the newsletter to cover.
The English name is Consensus Statement on Red Lines in Artificial Intelligence, and the Chinese name is 北京AI安全国际共识, which translates directly to Beijing AI Safety International Consensus.
China Newsweek is a magazine run by state paper China News Service. The “Intellectuals” platform was founded in 2015 by several professors.