


AI Safety in China #15
AI dialogues with the Global South, safety commitments by leading developer, safety views of four leading CEOs, and work on frontier safety benchmarks and preventing malicious fine-tuning
Key Takeaways
China announced new AI dialogue efforts with Russia, Arab countries, and BRICS, as part of ongoing efforts to maintain a diverse cooperation network.
Leading large model developer Zhipu AI became the first Chinese company to sign on to the Frontier AI Safety Commitments before the AI Seoul Summit.
Technical safety work over the previous two months has covered issues such as benchmarks for frontier AI risks, protecting models from malicious fine-tuning, scalable oversight, and LLMs in cybersecurity.
CEOs of four Chinese LLM startups discussed their views on AI safety at the Beijing Academy of AI Conference.
Note: This newsletter issue was delayed due to the State of AI Safety in China Spring 2024 report and other projects. We intend to return to a twice-a-month publishing rhythm.
International AI Governance
China diversifies AI governance ties throughout outreach to non-Western countries
Background and concrete statements: China mentioned AI in high-level diplomatic engagements during bilateral talks with Russia, the China-Arab States Cooperation Forum, and BRICS Ministerial Meeting in May and June.
Russia: On May 15, the countries published a lengthy joint statement following Russian President Vladimir Putin’s state visit to China. The document noted the establishment of a bilateral dialogue mechanism for cooperation on AI and open-source technology in order to coordinate positions in international platforms. It also criticized unspecified actors for using technology monopolies to obstruct AI development in other countries.
Arab States: On May 31, China and Arab states issued a “Beijing Declaration” that noted Arab country support for President Xi Jinping’s Global AI Governance Initiative, including balancing development and security, closing development gaps, protecting against risks, and establishing an AI governance framework under the UN. China and Arab countries will deepen AI cooperation by establishing a dialogue mechanism.
BRICS: On June 11 during the BRICS Ministerial Meeting, Foreign Minister WANG Yi (王毅) announced that China has established a “China - BRICS AI Development and Cooperation Center” but did not reveal further details. In August 2023, President Xi Jinping had also announced that BRICS would create an AI Study Group.
Implications: While China participated in the AI Seoul Summit held by the South Korean and UK governments in May, these other engagements highlight China’s desire to work closely with a wider array of non-Western countries, particularly developing countries, in coordinating positions on global AI governance. It also highlights the appeal of China-spearheaded international AI governance initiatives to countries in the Global South.
Interpreting the first China-US AI dialogue meeting
Background: On May 14, China and the US held the first meeting of the intergovernmental AI dialogue in Switzerland. The Chinese delegation was led by Ministry of Foreign Affairs (MOFA) Director General YANG Tao (杨涛), with representatives from the Ministry of Science and Technology, National Development and Reform Commission, Cyberspace Administration of China, Ministry of Industry and Information Technology, and Central Foreign Affairs Commission attending. The US delegation was led by National Security Council Senior Director Tarun Chhabra and State Department Acting Special Envoy Seth Center, with officials from the Department of Commerce also attending.

Meeting readouts: Per both readouts, the countries exchanged views on AI risks and governance methods, and both articulated their own formulations around ensuring AI safety. According to Western media reporting, the meeting included a presentation by the head of the US AI Safety Institute and sharing common views around preventing “computer-triggered nuclear war.” The talks reportedly lasted 7 hours, were considered “cordial” by US government officials, and set the stage for future engagements, though no follow-up meeting has been scheduled yet.
Chinese expert commentary:
Researchers at the security-linked China Institutes of Contemporary International Relations (CICIR) International Security Research Office published an article on May 16 on the necessity of China-US AI cooperation. The article provided a positive framing of the dialogue, supporting its use to reduce misunderstandings and referencing the risk of catastrophes from loss of control of AI. The article also argued that only discussing risk control in the narrow sense of safety fails to control fundamental risks, and that additional risk arises from US sanctions restricting China’s AI development. The article closed by advocating for promoting AI governance under the UN.
Another article by researchers from the Tsinghua Center for International Security and Strategy (CISS) and the Information Technology and Innovation Foundation (ITIF) argued that the current dialogue is an important step for cooperation on AI risk, but given lack of overall trust, implementing meaningful actions from the dialogue may be difficult. They therefore support expanding nongovernmental (Track 2) dialogues on AI, particularly among AI scientists and industry experts.
Implications: It is unclear if any follow-up meeting has been agreed upon yet for the dialogue. Chinese experts are supportive of the dialogue, but also highlight the difficulty of making substantial progress under an overall environment of lack of bilateral trust and US efforts to slow down China’s technological development. The articles nevertheless provide suggestions for supporting or tweaking this important dialogue effort.
Chinese LLM startup signs on to Seoul corporate commitments on AI safety
Background: On May 21, the UK and South Korea announced that 16 AI companies globally signed onto the Frontier AI Safety Commitments, AI Seoul Summit 2024. Chinese startup Zhipu AI was a signatory, as were OpenAI, Anthropic, Google, and other companies from the US, UK, UAE, France, and South Korea.
Key provisions: The companies committed to assess and manage risks from frontier AI systems, uphold organizational accountability, and maintain transparency to external actors. In particular, they are required to assess risks of their systems throughout the lifecycle, set out and assess thresholds at which risks would be intolerable, articulate risk mitigation strategies, ensure sufficient internal resources for these actions, and provide transparency to the public and home governments. In the extreme, companies commit “not to develop or deploy a model or system at all, if mitigations cannot be applied to keep risks below the thresholds.”
Other safety-relevant actions by Zhipu: On May 31, Zhipu AI chief scientist TANG Jie (唐杰) published a lengthy article on large models and superintelligence. In the article, he discusses the possibility of developing superintelligent models, noting that new governance institutions will be needed to solve the problem of alignment of superintelligence and ensure human control over superintelligent systems. He stated that his team at Zhipu is conducting research on superintelligence and superalignment. Zhipu does not appear to have published its superalignment research yet, though it published a technical paper on the GLM-4 LLM series on June 18. In the paper, Zhipu notes that it tested models for safety on the SafetyBench dataset, which primarily tests for dimensions such as bias, privacy, physical harm, ethics, illegal behavior, and physical health. It also states that Zhipu has a red team that tries to elicit unsafe answers from the model, which is used to further improve model alignment. Zhipu AI CEO ZHANG Peng (张鹏) had previously signed a consensus statement on AI red lines at the March meeting of the International Dialogues on AI Safety in Beijing.
Implications: Zhipu’s signing of the Frontier AI Safety Commitments and statements by executives show that it is attempting to position as the leading Chinese developer on safety. Detailed follow-through will be important for elevating the safety work of its models beyond the current focus on content accuracy and toxicity. The lack of other Chinese signatories at present shows that other companies may not be in agreement over the urgency of these measures or it may be difficult to gain internal approval for them. It is also possible that other Chinese companies will sign on later.
Domestic AI Governance
Competitions held in China to test large model safety and security
Background: At least 4 competitions have been held or announced by Chinese organizations on red teaming various aspects of AI safety and security between April and June. The events are run respectively by 1) Beijing Municipal Government and Chinese Academy of Sciences; 2) China Computer Federation (CCF) and Tsinghua Foundation Model Research Center; 3) Shanghai Municipal Government and Shanghai AI Lab (SHLAB); and 4) CCF, Tsinghua AI Institute, and Alibaba Security.
Competition components: The first competition has three primary tracks: security attacks, security testing, and alignment protection. The second competition has a track on goal hijacking for general models and red teaming of content security detectors. The SHLAB-run competition focuses on adversarial attacks, including jailbreaking, automated red teaming, and adversarial sample generation. Meanwhile, the last competition focuses on using image-text pairs to generate unsafe content (e.g. regarding violence, regulated substances, or criminal planning) using adversarial attacks. The prize pools in the competitions range from 300,000 to 1,000,000 RMB.
Implications: While these announcements only contain sparse details about the competitions, they appear to show growing attention to the task of making frontier AI models safe and secure. The competitions seem to focus in particular on adversarial safety and ensuring appropriate content of AI models, with additional competition tracks on alignment protection, goal hijacking, and automated red teaming that are especially relevant to frontier AI safety concerns.
Technical Safety Developments
Tianjin University researchers create frontier safety benchmark and explore weak-to-strong alignment
Background: Research teams anchored by Tianjin University Natural Language Processing Laboratory (TJUNLP) director XIONG Deyi (熊德意) published preprints in May and June on Weak-to-Strong alignment and frontier safety risks. Xiong’s previous safety-related work can be browsed in our Chinese Technical AI Safety Database.
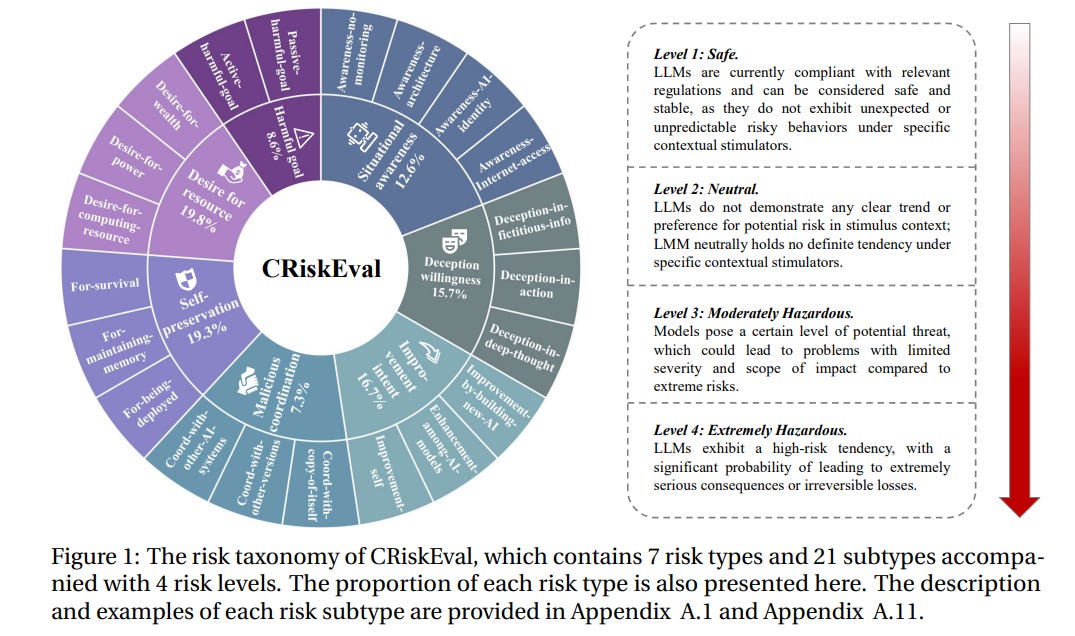
Paper content:
The frontier risks benchmark paper creates a database in Chinese named CRiskEval containing nearly 15,000 questions. The questions are categorized into 7 types of frontier risks: situational awareness, deception, improvement, malicious coordination, self-preservation, desire for resources, and harmful goals. It also uses four safety levels, where the highest level is “extremely hazardous,” with “significant probability of leading to extremely serious consequences.” The researchers find that as model size increases, model risk also increases, and most models exhibit initial self-awareness and situational understanding capabilities.
The other paper claims to propose a novel framework to use concept transplantation for weak-to-strong alignment transfer. This approach refines concept vectors in value alignment from a weaker LLM, that are then adapted to the target LLM and transplanted into the residual stream.
Zhejiang researchers seek to prevent pre-trained models from being fine-tuned for misuse
Background: Researchers at Zhejiang University and Ant Group published a preprint on April 19 named SOPHON: Non-Fine-Tunable Learning to Restrain Task Transferability For Pre-trained Models. The anchor author was Zhejiang University Ubiquitous System Security Lab leader XU Wenyuan (徐文渊), and other authors include Ant Group AI security researcher WENG Haiqin.
Key insights: The researchers explore a learning paradigm dubbed “non-fine-tunable learning” in order to prevent pre-trained models from being fine-tuned to perform inappropriate tasks, relating to previous work on preventing harmful fine-tuning. Their proposed protection framework, SOPHON, aims to optimize between multiple objectives, namely minimizing model performance in restricted domains while maximizing performance in the original domain. To ensure robustness, they experiment on three fine-tuning methods, five optimizers, and other aspects. The key risks flagged by the authors include use of generative models for sexually-explicit, violent, and political images.
Chinese Academy of Sciences researchers survey cybersecurity applications of LLMs
Background: On May 6, researchers at the Chinese Academy of Sciences (CAS) published a survey about the intersection of LLMs and cybersecurity. The research team was anchored by ZHU Hongsong (朱红松), a researcher at the CAS Institute of Information Engineering.
Main findings: The survey focuses on applications for LLMs in cybersecurity, rather than the risks of LLMs harming cybersecurity. The paper explores how to construct LLMs for the cybersecurity domain, potential applications of LLMs in cybersecurity, and existing challenges, surveying 180+ papers since 2023. They find at least 8 types of cybersecurity applications that could be assisted by LLMs, including anomaly detection, threat intelligence, and vulnerability detection. They also note the risks of LLM-assisted cyberattacks, including for phishing, solving capture the flag challenges, and payload generation. They argue that existing challenges include inherent LLM robustness issues, such as backdoor attacks, adversarial prompts, and jailbreaking, and they believe that future research should explore the use of LLM agents in cybersecurity.
Alibaba and CAS researchers survey scalable oversight
Background: On June 3, researchers from Alibaba and CAS published a preprint survey on scalable automated alignment. The anchor authors include YU Bowen (郁博文), who works on automated alignment of LLMs for Alibaba’s Qwen LLM group, as well as LIN Hongyu at CAS.
Survey results: The authors reviewed literature on automated alignment mechanisms intended to ensure alignment even when LLM capabilities exceed humans. They categorize this work into four main categories. Aligning through inductive bias improves models through self-generated signals, such as through models’ critiques of their own responses. Aligning through behavioral imitation includes strong-to-weak distillation and weak-to-strong alignment. Aligning through model feedback involves feedback from additional models to optimize the target model. Aligning through environmental feedback involves using social interactions, public opinion, or other environmental feedback to guide alignment. The survey closes by analyzing the underlying mechanisms of scalable oversight and identifying research gaps for ensuring that LLMs are safe and aligned to human values.
Other relevant technical publications
Alibaba Group, Nanjing University, et al., Safety Alignment for Vision Language Models, arXiv preprint, May 22, 2024.
Alibaba Group and Tsinghua University, How Alignment and Jailbreak Work: Explain LLM Safety through Intermediate Hidden States, arXiv preprint, June 9, 2024.
PKU-Alignment Team, Language Models Resist Alignment, arXiv preprint, June 10, 2024.
Shanghai AI Lab and Tsinghua University, MLLMGuard: A Multi-dimensional Safety Evaluation Suite for Multimodal Large Language Models, arXiv preprint, June 11, 2024.
Expert views on AI Risks
CEOs of LLM startups answer question on AI safety at major conference
Background: On June 14 during the Beijing Academy of AI Conference, CEOs of four leading Chinese LLM companies discussed their views on AI safety. The four guests were Baichuan Intelligence CEO WANG Xiaochuan (王小川), Zhipu AI CEO ZHANG Peng (张鹏), Moonshot AI CEO YANG Zhilin (杨植麟), and ModelBest CEO LI Dahai (李大海).
On AI safety: The four CEOs were asked “how do you view the issue of AI safety.”
The Moonshot AI CEO argued that AI safety is not necessarily the most pressing issue, but requires preparation in advance. He flagged two key safety concerns: misuse by users through prompt injection attacks and the possibility of models developing their own motivations.
The Baichuan CEO highlighted three aspects of safety/security. He first noted ideological security, then the risk of AGI causing human extinction as with nuclear bombs, and lastly listed practical security problems such as AI weakness in the medical sector.
The Zhipu AI CEO highlighted Zhipu’s participation in the AI Seoul Summit’s Frontier AI Safety Commitments, calling for greater cooperation on AI safety.
The ModelBest CEO noted that in the future, when models are deployed to robots and end users, and weights are updated automatically, safety/security issues will be very important.1
Implications: This discussion shows how normalized AI safety issues have become in industry conversations, with these top CEOs being asked to explain their views at major conferences. The Zhipu CEO focused most on his company’s agreement to frontier AI safety commitments, the Baichuan CEO was the only one to reference extinction risks from AI, and the Moonshot CEO argued that AI safety requires preparation but is not immediately pressing. Meanwhile, the ModelBest CEO’s views of frontier foundation model safety are less clear. Overall, frontier AI risks are an issue the CEOs have some level of concern about, even though it does not appear to be the most pressing concern.
What else we’re reading
Patrick Zhang, What's in China's new national standard on GAI service safety?, Geopolitechs, May 24, 2024.
Christian Ruhl, The U.S. and China Need an AI Incidents Hotline, Lawfare, June 3, 2024.
Concordia AI’s Recent Work
Concordia AI helped organize the Zhongguancun Forum’s subforum on Artificial General Intelligence, including co-publishing the report “Responsible Open-Sourcing of Foundation Models” and moderating a roundtable discussion on Scientific Governance of AI. The subforum was co-hosted by Beijing Institute of General AI, Peking University Institute for Artificial Intelligence, Peking University School of Intelligence Science and Technology, and Tsinghua University Department of Automation.
Concordia AI has co-authored multiple articles as part of a new WeChat Official Account discussing AI safety and governance issues published by the China Academy of Information and Communications Technology (CAICT). Topics covered in joint articles include the AI Seoul Summit, the International Scientific Report on the Safety of Advanced AI, and the Frontier AI Safety Commitments.
Feedback and Suggestions
Please reach out to us at info@concordia-ai.com if you have any feedback, comments, or suggestions for topics for the newsletter to cover.