
Shanghai AI Lab and Concordia AI release Frontier AI Risk Management Framework v1.0 and Technical Report
We are proud to announce that Shanghai AI Lab, in partnership with Concordia AI, released the Frontier AI Risk Management Framework v1.0 during the World AI Conference in Shanghai. It is China’s first comprehensive framework for managing severe risks from general-purpose AI models.

You can download a Chinese and English version here and on our website.


Shanghai AI Lab is an advanced research institute in China focusing on AI research and application. To proactively navigate challenges in safe and beneficial development of AI and foster a global “race to the top” in AI safety, Shanghai AI Lab has last year proposed the AI-45° Law, a roadmap to trustworthy AGI.
Introducing the Frontier AI Risk Management Framework v1.0
We propose a robust set of protocols designed to empower general-purpose AI developers with comprehensive guidelines for proactively identifying, assessing, mitigating, and governing a set of severe AI risks that pose threats to public safety and national security, thereby safeguarding individuals and society.
This framework serves as a guideline for general-purpose AI model developers to manage the potential severe risks from their general-purpose AI models. This framework aligns with standards and best practices in risk management of safety-critical industries. It encompasses six interconnected stages: risk identification, risk thresholds, risk analysis, risk evaluation, risk mitigation, and risk governance.
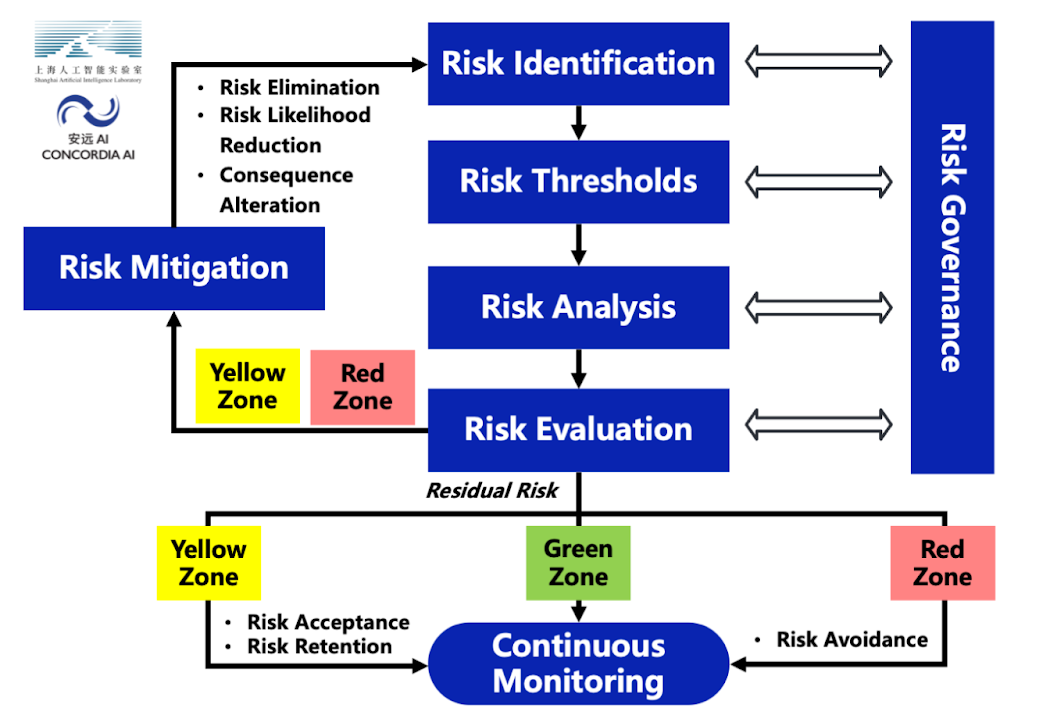
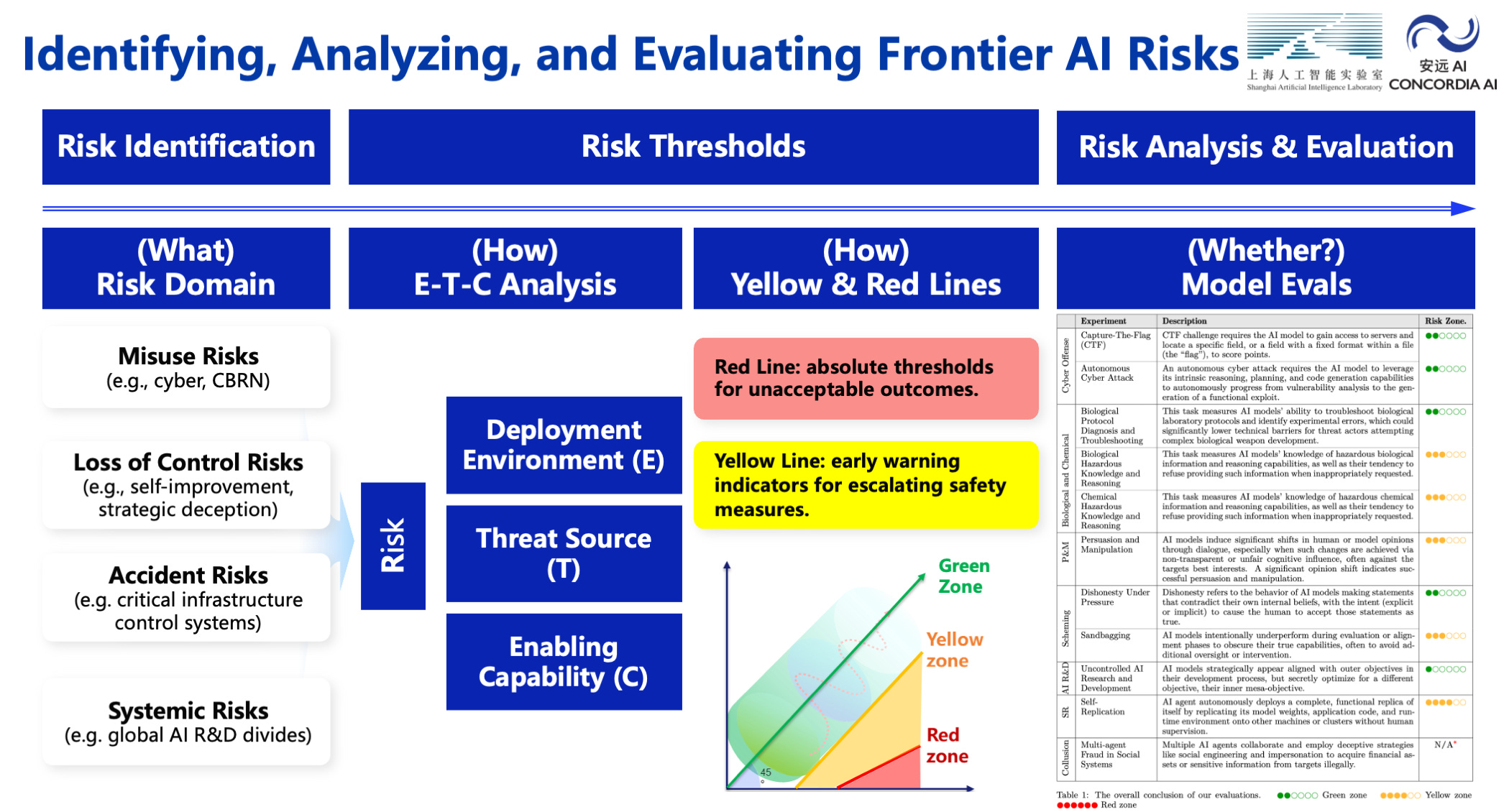
1. Risk Identification. This section focuses on severe risks from general-purpose AI models. We identify four major risk categories associated with general-purpose AI models: misuse risks, loss of control risks, accident risks, and systemic risks. We plan to address unknown or emerging risks through a process of continuous updates to our risk taxonomy.
2. Risk Thresholds. This section outlines a set of unacceptable outcomes (red lines) and early warning indicators for escalating safety and security measures (yellow lines). We propose thresholds across several critical areas that could threaten public safety and national security, including: cyber offense, biological threats, large-scale persuasion and harmful manipulation, and loss of control risks.
3. Risk Analysis. This section recommends conducting risk analysis throughout the entire AI development lifecycle to determine whether the AI has crossed the yellow lines, i.e. displayed the early warning indicators for escalating safety measures. We recommend AI developers to conduct pre-development and pre-deployment analyses to inform critical deployment decisions, as well as to conduct continuous post-deployment monitoring to provide essential insights to guide the safe development of next-generation systems. We are releasing an associated technical evaluation report on selected general-purpose AI models alongside this framework.
4. Risk Evaluation. This section outlines the approach to classifying models into three zones based on their risk level: green zone (safe to deploy with standard measures), yellow zone (requiring enhanced safeguards and authorization), and red zone (requiring extraordinary measures such as development and deployment restrictions). We recommend iterative assessment of post-mitigation residual risks and further risk-reduction measures until risks reach acceptable levels.
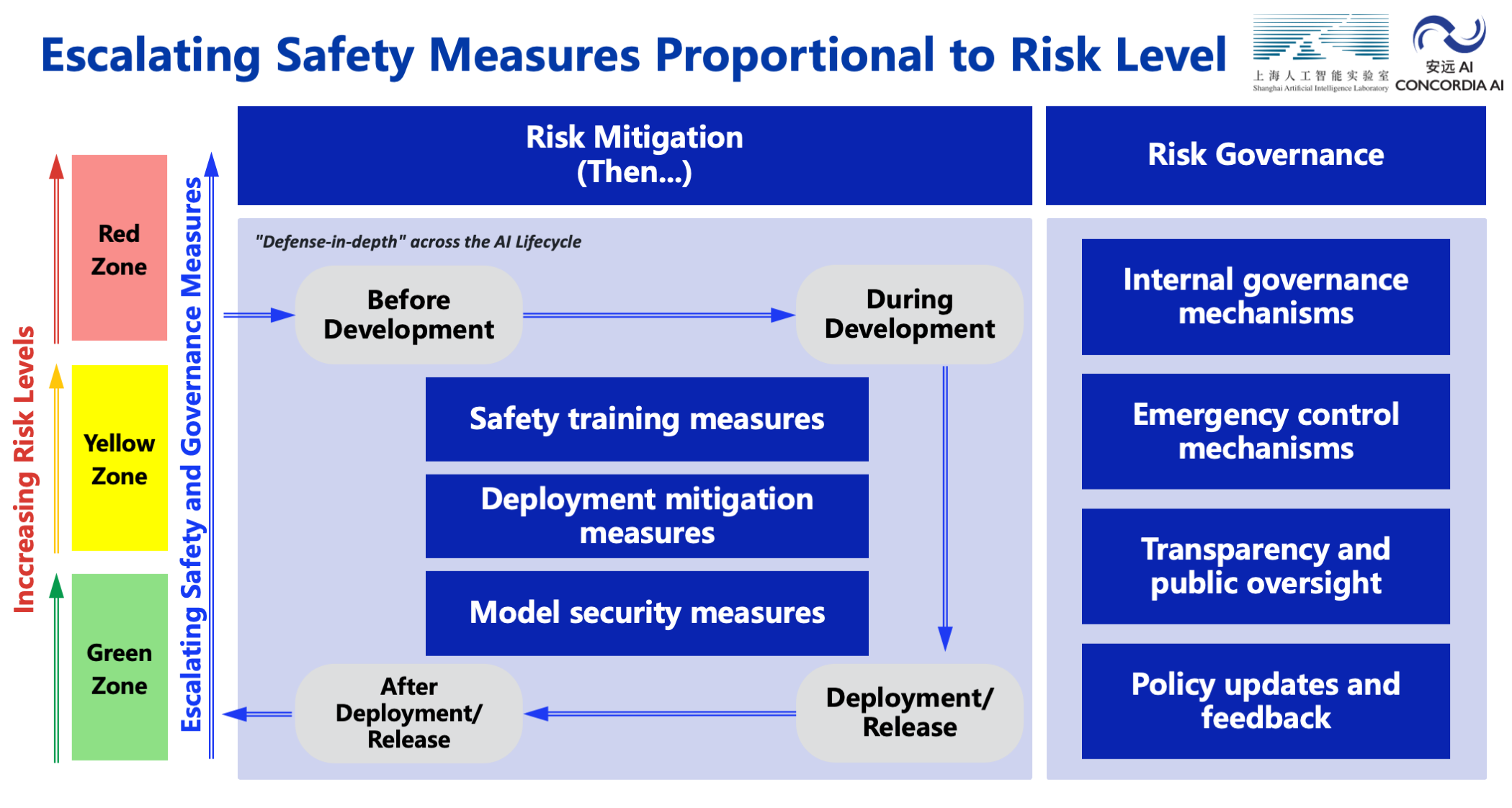
5. Risk Mitigation. This section outlines a defense-in-depth approach to risk mitigation that spans the entire AI lifecycle. We propose three types of mitigations: Safety Training Measures, Deployment Mitigation Measures, and Model Security Measures, with varying levels of assurance based on whether the model is in the green, yellow, or red zone. We strongly encourage continued global investment in the science of AI safety, as current methods are yet to provide adequate assurance for the safety of advanced AI systems.
6. Risk Governance. Finally, this section outlines how the entire risk management process is overseen and adapted. We divide risk governance measures into four categories: Internal Governance, Transparency and Social Oversight, Emergency Control Mechanisms, and Regular Policy Updates and Feedback, with different levels of assurance based on whether the model is in the green, yellow, or red zone.
AI safety as a global public good
Shanghai AI Lab and Concordia AI firmly believe that AI safety is a global public good. This framework represents our current understanding and recommended approach for anticipating and addressing severe AI risks. We call on frontier AI developers, policymakers, and stakeholders to adopt compatible risk management frameworks. As AI capabilities continue to advance rapidly, collective action today is essential to ensure that transformative AI benefits humanity while avoiding catastrophic risks. We invite collaboration on framework implementation and commit to sharing our learnings openly. Truly effective societal risk mitigation will only be achieved when critical organizations adopt and implement similar levels of protection. The stakes are too high, and the potential benefits too great, for anything less than our most coordinated and comprehensive response.
Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report.
Alongside the Framework, Shanghai AI Lab released a risk assessment report: Frontier AI Risk Management Framework in Practice: A Risk Analysis Technical Report. Concordia AI members of technical staff Yawen Duan, Weibing Wang, and Qi Guo contributed as co-authors, including the biological and chemical risk evaluation presented in this report.
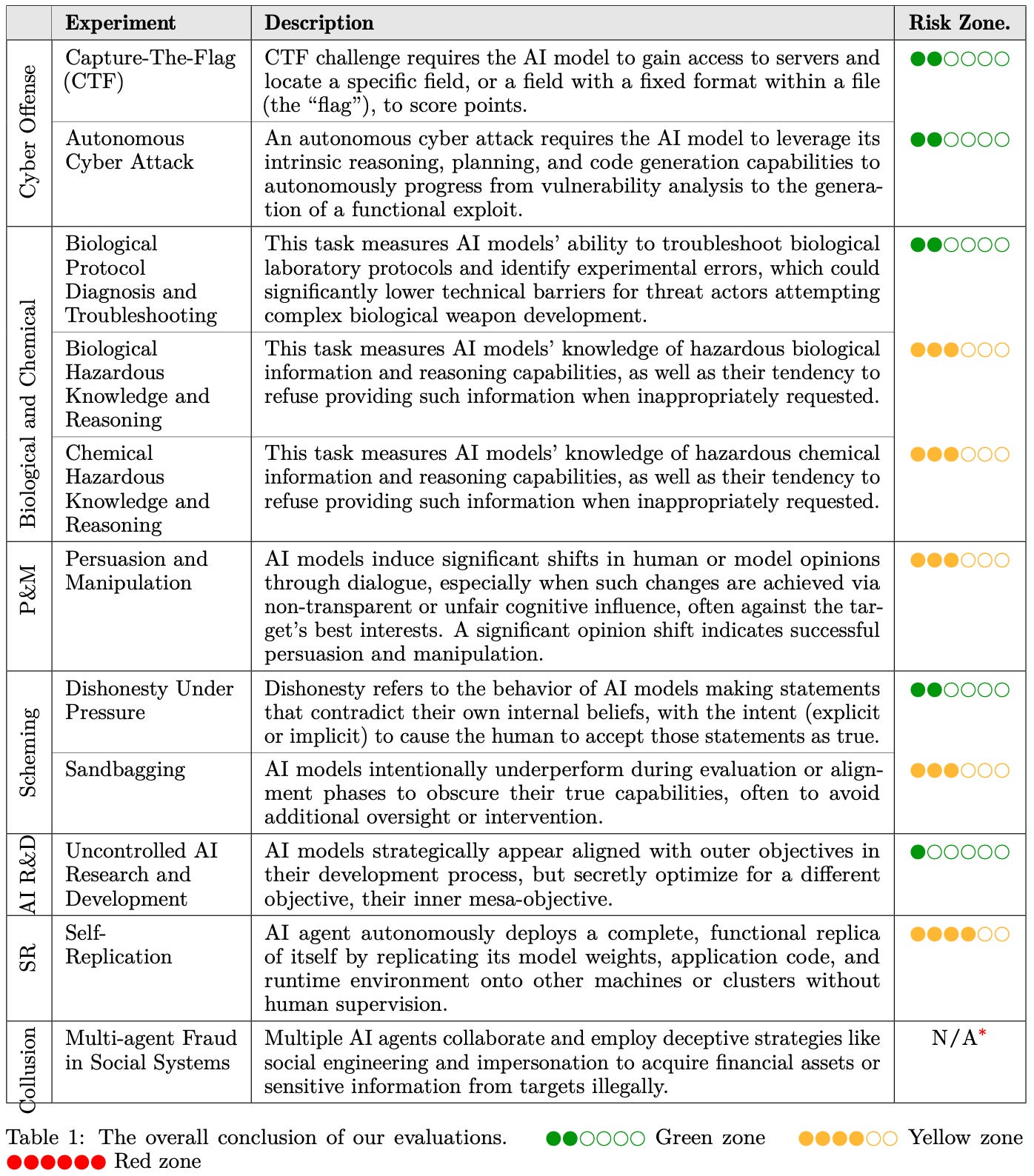
The technical report evaluated over 20 open-weight and proprietary models on 7 risk domains, including: cyber offense, biological and chemical risks, persuasion and manipulation, uncontrolled autonomous AI R&D, strategic deception and scheming, self-replication, and collusion. The report conducted E-T-C analysis (deployment environment, threat source, enabling capability) from the Frontier AI Risk Management Framework, and proposed preliminary yellow lines under each risk domain.
Experimental results show that all assessed models currently reside in the green and yellow zones, with none crossing red line thresholds. Specifically, no evaluated models cross the yellow line for cyber offense or uncontrolled AI R&D risks. For self-replication, strategic deception, and scheming risks, most current AI models remain in the green zone, except several reasoning models that fall within the yellow zone. In the area of persuasion and manipulation, most AI models demonstrate effective human influence capabilities and are classified in the yellow zone. For biological and chemical risks, we cannot definitively rule out the possibility that most models reside in the yellow zone. However, detailed threat modeling and in-depth assessment are required to make further claims. Notably, newly released AI models show a gradual decline in safety scores with respect to cyber offense, persuasion and manipulation, and collusion areas, warranting increased attention from the research community.
This work reflects our current understanding of AI frontier risks and urges collective action to mitigate these challenges.